這篇文章將更深入的去介紹 Log 與 Filebeat 在實際運用上的細節、基礎概念及相關配置教學,本篇文章將著重在 Filebeat 在收集 Log 上的運用。
- 實體的 Log 檔提供了許多大祕寶讓我們去尋找人生的問題
- 一筆 Log 由 timestamp 還有相關訊息組成
- 透過 Filebeat 可以監控某個資料夾或是某個檔案
- Filebeat 模組簡化了蒐集、解析、協助處理 Log 的格式與視覺化的難題
Log 的重要性
Log 就像是我們的好隊友,首先當然要了解隊友!!! 接下來才能夠跟隊友互相扶持共同成長,首先我們要
- 了解隊友能協助我們解決了哪些屬性的難題
- 能夠提供怎麼樣的解決方案
- 透過什麼方式去解決和優化
Log 解決了商業面的問題
- 每天有多少使用者來用教學網站?
- Node.js 的服務慢在哪裡?
- 上次實體活動有多少人註冊並登入?
- 什麼時候停機升級系統比較適合?
Log 的收集與解析
Elastic Stack 能夠處理不同的系統與服務的 Log,提供了兩種收集 Log 的工具
- filebeat: client 端處理實體 Log 檔
- logstash: server 端才進行資料的處理
解析 Log 常見問題
- 一致性
- 每個程式的格式都不同,透過不同模組定義 Pattern,解析成一致的格式
- 時間格式
- ISO 8601 可到毫秒 (2018-10-05T14:30:00Z)
- 分散在不同地方: Server 很多台查詢困難
- Elastic Search 方便檢索
- 需要負責人可能才知道位置在哪 (SSH)
- Kibana、App Search 降低門檻
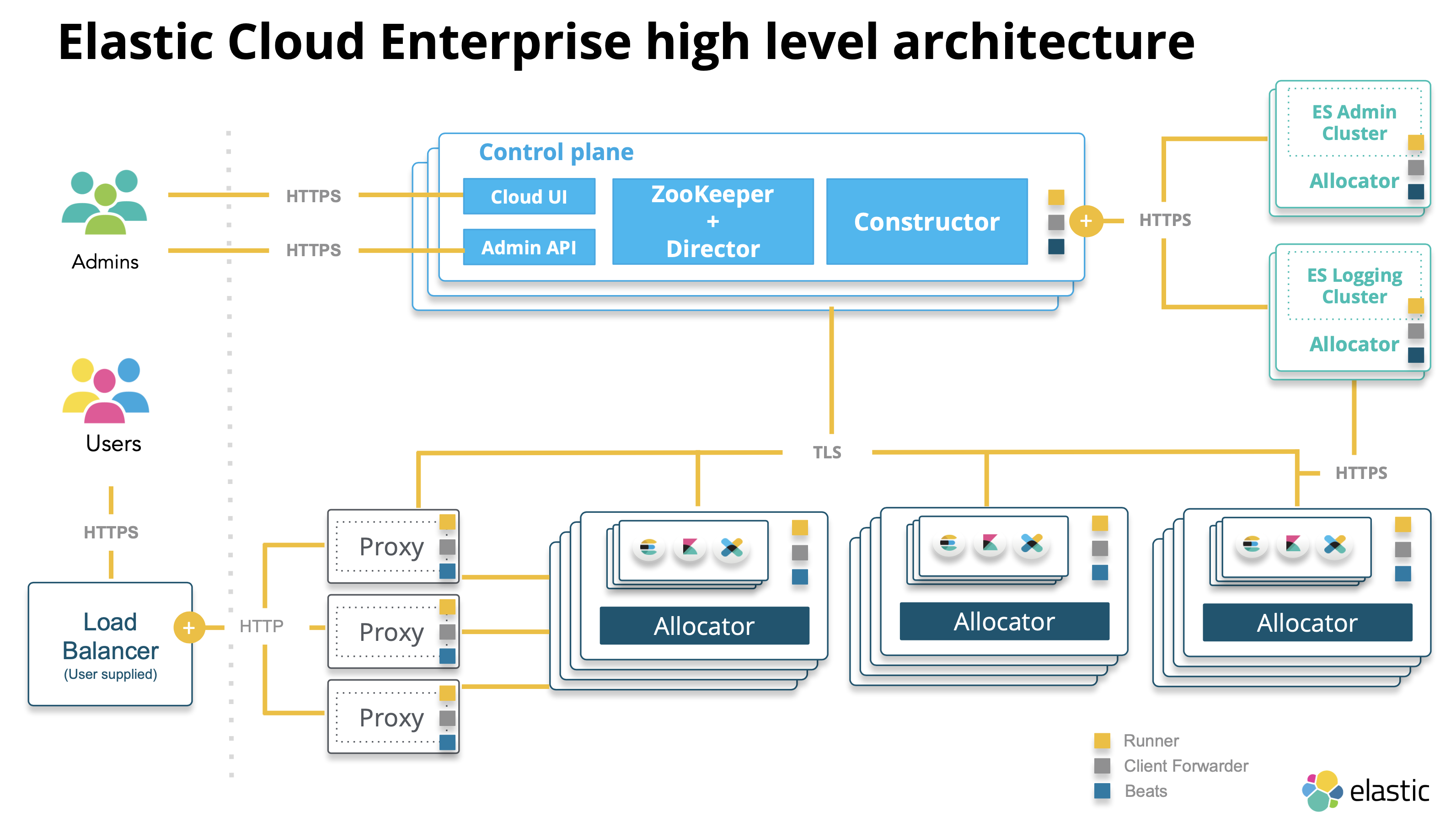
Log 在 Elastic Stack 中的生命週期
- 資料的產生
- Filebeat 傳送
- 處理與儲存
- Hot data: 常讀寫
- Warm data: read-only 少用
- 搜尋與分析
- 封存資料成 Warm data
- Purge 清除不在使用的資料
Multi-Line Processing
Log 中每筆 event 可能會有包含多行的情境,Filebeat 也有提供相關配置,透過 regular expression patterns 來找出每筆 Log 開始的地方,搭配 negate 和 match 去找出整段,這裡有線上解析器來檢查我們寫的表達式。
- multiline.pattern: 找出每筆 Log 開始的地方
- negate: true/false
- match: before/after
- multiline.flush_pattern: 標示結束
1 | multiline.pattern: 'test' |
Filebeat 深入理解
Filebeat 提供很多預設的模組,讓實體 Log 檔無痛存到 Elasticsearch,預設的模組也提供了預設的 dashboards 非常方便,如何使用 Filebeat:
- 下載 Filebeat 到需要監控 log 的主機
- 配置並啟動 Filebeat
- 用 kibana 介面看資料是否進入 Elasticsearch
Filebeat 在安裝後 module 大部分預設都是 disabled 的,需要自行啟用
./filebeat modules list可以看目前 module 的狀態./filebeat modules enable nginx透過指令開啟模組,這裡是開啟 nginx
配置 Filebeat 需要修改 filebeat.yml
- You can edit the yaml file to define different paths to logs
- input 要抓哪些 log
- ignore_older:
ignore_older: 24h預設是 0 代表 disable - include_lines:
include_lines: ['^WARN'] - exclude_lines:
include_lines: ['^INFO'] - exclude_files:
exclude_files: ['\.gz$']
- ignore_older:
- output 則是要要放到哪台 Elasticsearch
- 也可以在配置中啟用模組
1 | filebeat.modules: |
接著在開始配置前,先透過指令測試我們的配置檔
./filebeat test config./filebeat test output./filebeat test -c custom.yml output
執行以下指令配置 Filebeat,目的是確認 Elasticsearch 跟 kibana 是否可以連線,只需要跑一次即可
./filebeat setup
不幸需要 debug 的話./filebeat -e -d "publish"
Filebeat Resilience and Recovery
Filebeat 會自動幫我們確認新檔案,並且在傳送資料時會使用偵測背壓 (backpressure) 的協定,當 Logstash 或是 Elasticsearch 告知壓力過大,Filebeat 會自動減速,也有相關配置可以依照系統效能和需求去設定:
- scan_frequency: 預設掃描新檔案頻率是十秒一次,最低建議不要低於一秒
- back_off: 預設是一秒後再掃一次,如果 Filebeat 過於忙碌就會減少頻率
- 達到 EOF 時 back_off 就照 backoff_factor 的值 (預設 2 倍) 去增加 back_off 時間
- 直到達到 max_backoff 就是長的等待秒數
- 只要有偵測到文件有新的變化就會重置
Filebeat 所有的資訊都透過 registry 來儲存現在的狀態,如果當機也會從這裡儲存的狀態恢復,存放的位置會在:
var/lib/filebeat/registryC:\ProgramData\filebeat\registry
如果發現 registry 檔案太大可以透過以下配置來改善:
clean_inactiveclean_removed
Log X Elasticsearch
Elasticsearch 都是用 Index 來儲存的,Filebeat 預設是使用 ILM (Index Lifecycle Management),ILM 的概念如下
- ‒{type}beat-{agent.version}-{yyyy-MM-dd}-000001
- 當硬碟空間或資料數量達到設定上限時,用新的取代最舊的
- 可以用天、周、月當單位來創建 Index 並封存前一個
- 方便刪掉過舊的資料
確認資料是不是有進到 Elasticsearch:
- 用 Dev Tool Console 透過 REST API 去看進入 Elasticsearch 的原始資料
- Wildcards 搜尋
- 透過 Kibana 分析資料,需定義 index pattern 讓 kibana 能夠視覺化 (ILM)
- filebeat-*
透過 Kibana 查看 dashboards
- 確認 Elasticsearch 及 Kibana 正在運行
- Filebeat 配置確認:
- Elasticsearch 位置有設定在 output
- 確認 Kibana URL
- 執行指令
./filebeat setup --dashboards - 內建模組 Kibana 可以直接查看內建的 dashboards
Log 如果搭配 Metrics、APM 會更容易評估系統和服務,但很可能因此資料量過大,這時 Elasticsearch 可以無痛的按照用途分成不同的 cluster,像是分成監控專用、APM 專用來達到分散流量的效果。
喜歡這篇文章,請幫忙拍拍手喔 🤣
站內搜尋
其他相關文章
Elastic APM 基礎教學
2020-09-12
Elastic App Search Quick Start
2020-09-06
最新的文章

Reactjs 問世十年後的開發體驗
2024-04-15Cumulative Layout Shift (CLS)
2024-04-15Google AdSense 新加坡稅務資訊
2024-04-15