Elastic Cloud Enterprise 維運與除錯
這篇文章會示範如何透過 Elastic Cloud Enterprise 配置高可用性 (High Availability) 的系統架構,透過架構設計來消除單點故障的影響來提升網站的可靠性。除錯其實就是維運團隊的日常任務,當然有些公司的維運可能只會
- 重開虛擬機加重啟服務
- 寄信然後跟主管一起用嘴高光負責的 RD
不過一個稱職的維運通常可能還會給力的幫忙
- 幫忙上補釘或是緊急修復系統異常
- 日常的系統底層服務或軟體更新
- 協助啟用新的附加功能,譬如加密傳輸
ECE 基本維運除錯
ECE 目前體驗下來的心得是有好用方便的 UI,而且透過 Docker 容器化的配置也解決了一部分早期分散式系統會遇到的多租戶 (Multi-Tenancy)、腦裂 (split brain) 等等關於實體資源分配搶奪的問題,缺點大概就是目前還沒有 logstash? 不過這次 30 天體驗也沒怎麼使用到,其實大多狀況看起來也都可以處理得很好?
接下來會示範怎麼在不影響原來的服務的前提下,怎麼安全的去維護 ECE 中的元件服務。透過 Cloud UI 的介面,可以初步方便簡單觀察各個服務叢集目前的狀況,符號會有三種顏色,綠色正常、黃色警告、紅色不正常。
符號會有三種顏色,綠色正常、黃色警告、紅色不正常
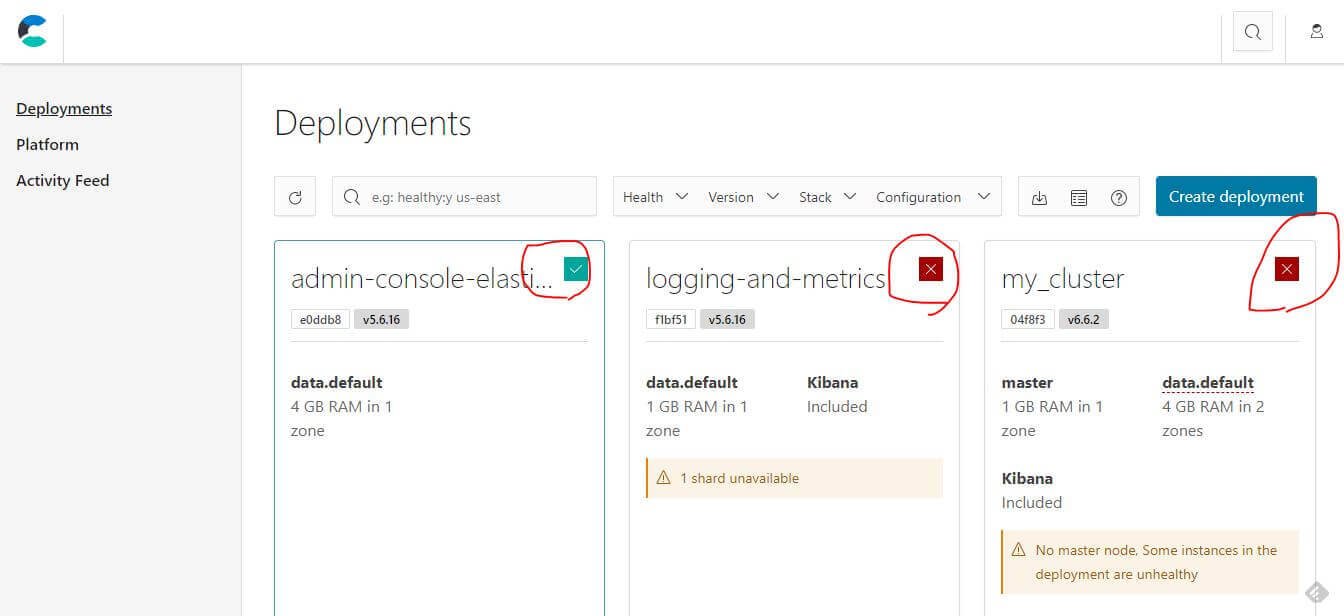
正常在做維護或除錯的時候,理論上不應該影響原來系統的運行,會影響的話現在的 SA/SD 就應該去撞豆腐了? 接下來的示範中目前有三個可用區域,假設我們今天要進行第二個可用區域的相關維護。
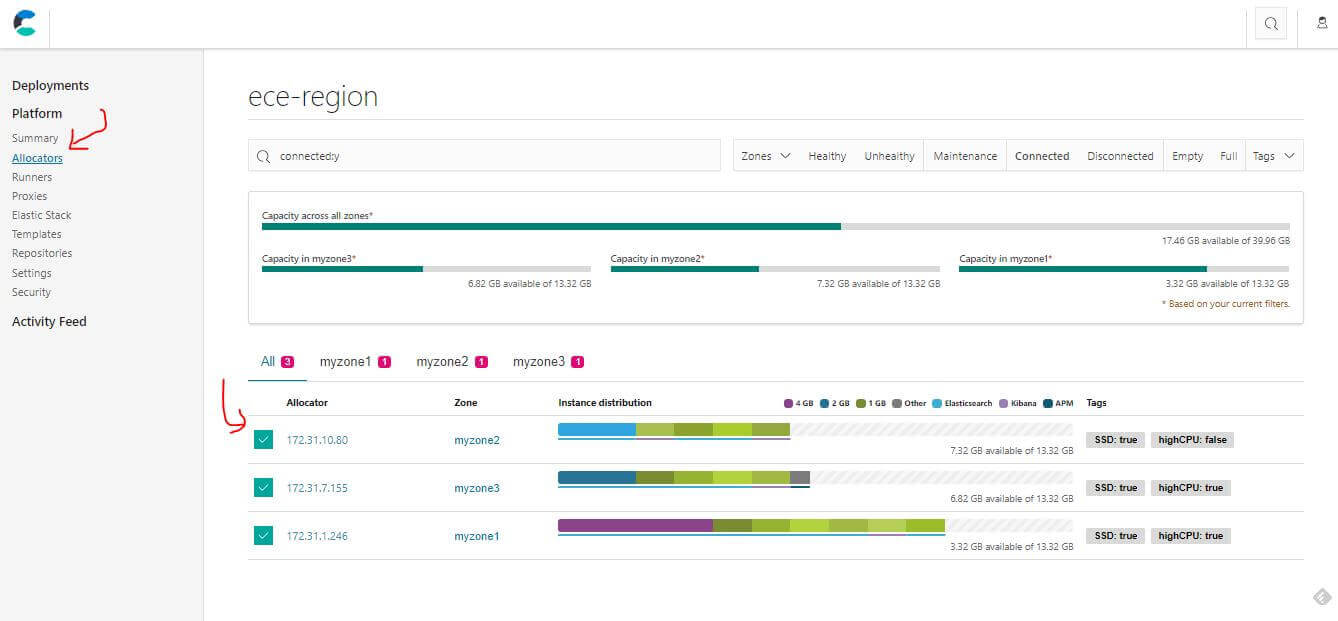
第一個步驟進到 Allocators 選單找到第二個可用區域並啟動維護模式。
Allocators 選擇 zone 2 進行維護
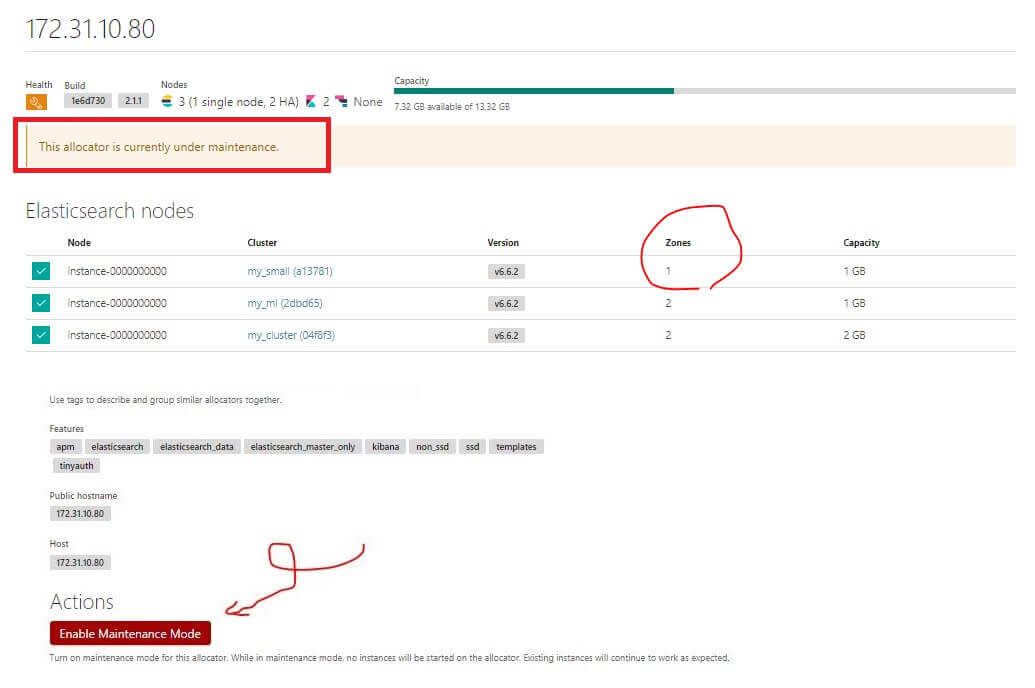
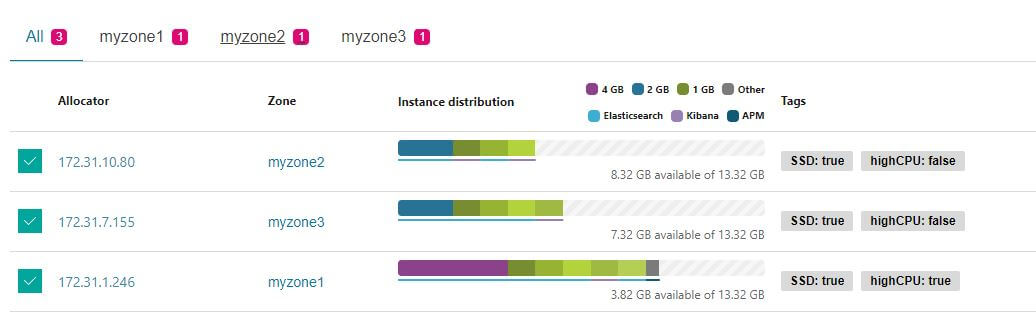
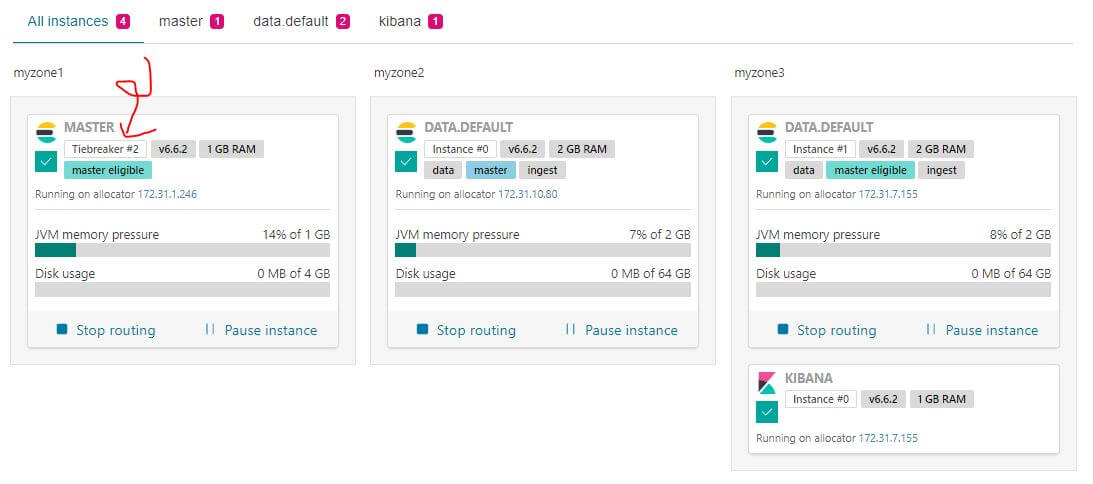
啟動後會發現只有一個服務節點是只存在這個可用區域,這就是這次要移動的對象,有兩個 zone 以上的不需要移動,因為會有 Tiebreakers 幫忙自動做 HA,所以在真的停機之後會影響的就是這個節點的服務。
找出在這個可用區域且只有 1 zone 的服務
嘗試進行移動
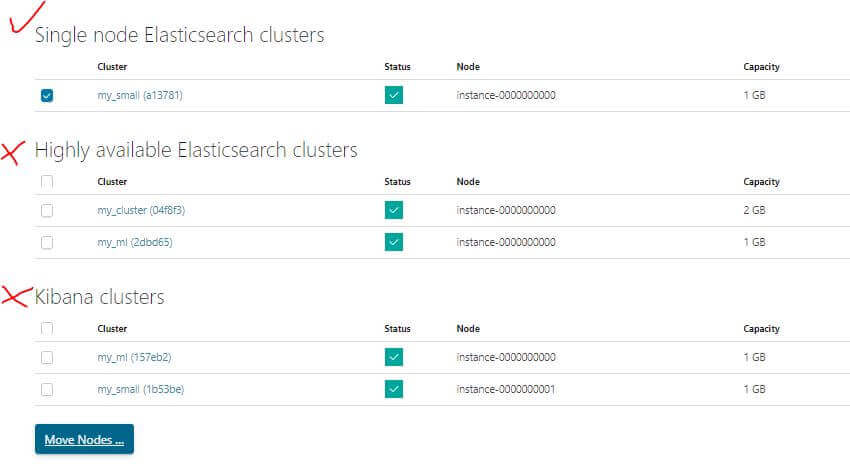
移動的時候可能會發現一點小問題
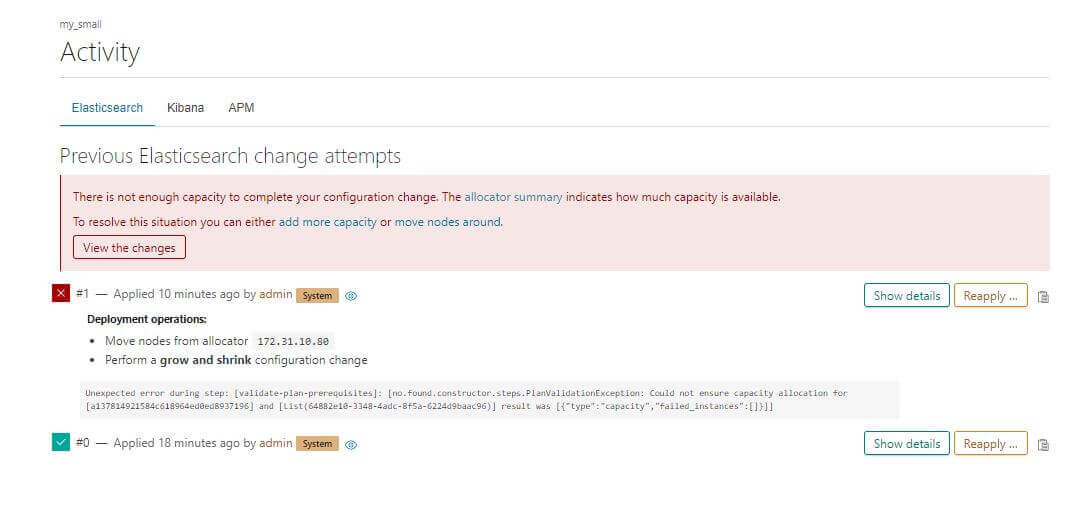
會發現是沒有對應的可用區域可以移動,這邊就先簡單修改 Tag,把 highCPU 改成 false 就可以移動了
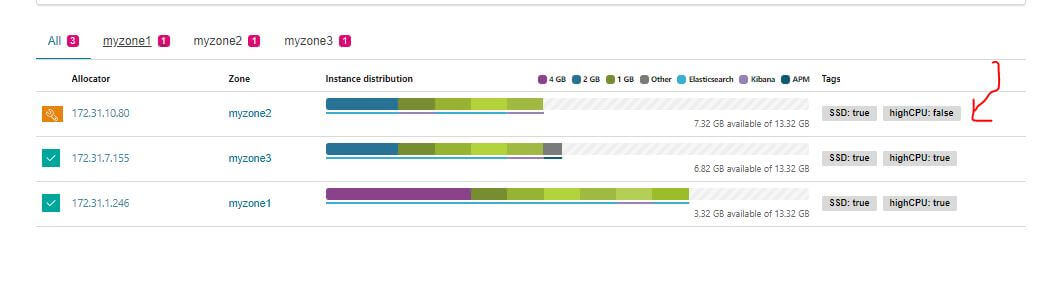
移動完成後假裝進行維護,把 Docker 停掉並重開機

會發現可用區域就不見了
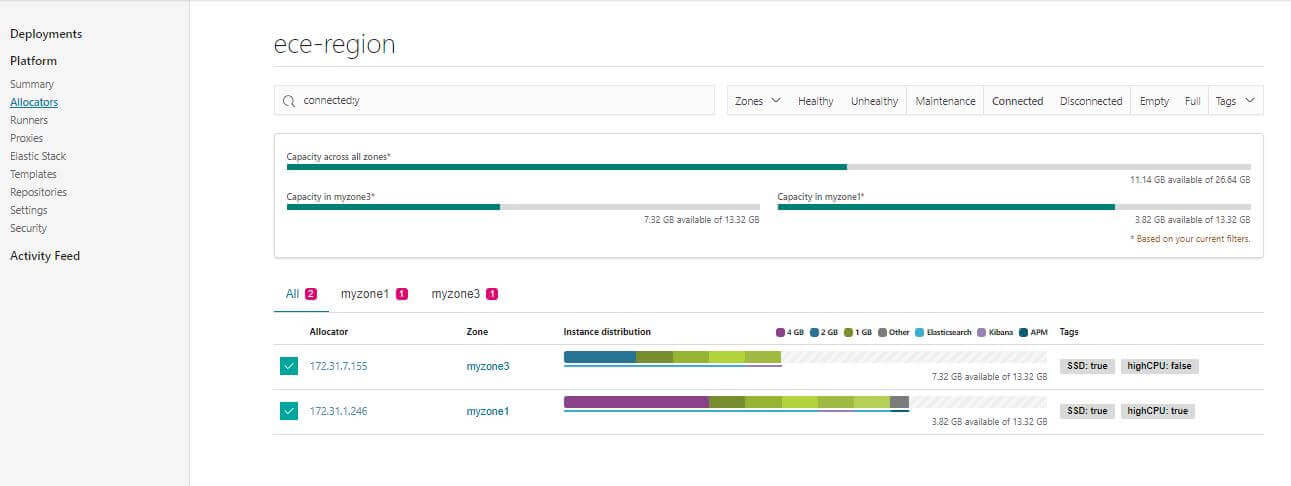
等重開機完成後啟用 Docker 取消維護服務後,Tiebreakers 會自動讓節點服務恢復,收工 🎉🎉🎉
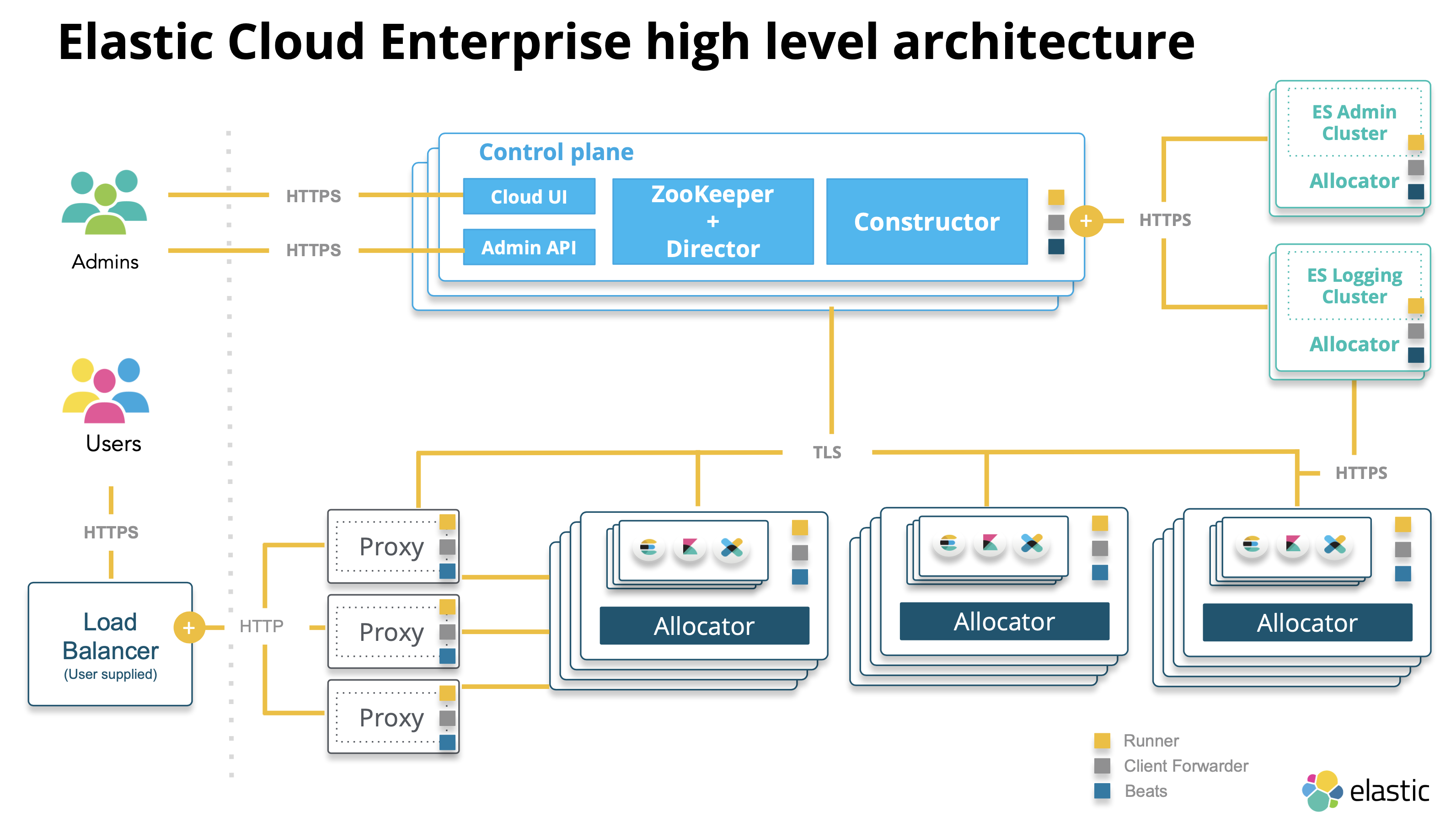
High Availability
ECE 的高可用性主要是透過可用區域 (availability zones) 來做到容錯與高可用性的,可用區域可以是任何雲端或是實體機台,每個區域皆由一或多個配備獨立電力、冷卻系統及網路的資料中心所組成,且不被其他區域的狀況影響,像是如果地震導致台北區停機,東京區系統應該還是要維持正常。
ECE 配置可用區域
安裝時透過 --availability-zone 這個指令來加入可用區域,安裝步驟如下:
安裝第一台,跟之前一樣安裝完之後會有帳號、密碼還有 token 相關訊息,記得存好,指定 --availability-zone myzone1。
bash <(curl -fsSL https://download.elastic.co/cloud/elastic-cloud-enterprise.sh) install --cloud-enterprise-version 2.1.1 --availability-zone myzone1
安裝第一台成功的訊息
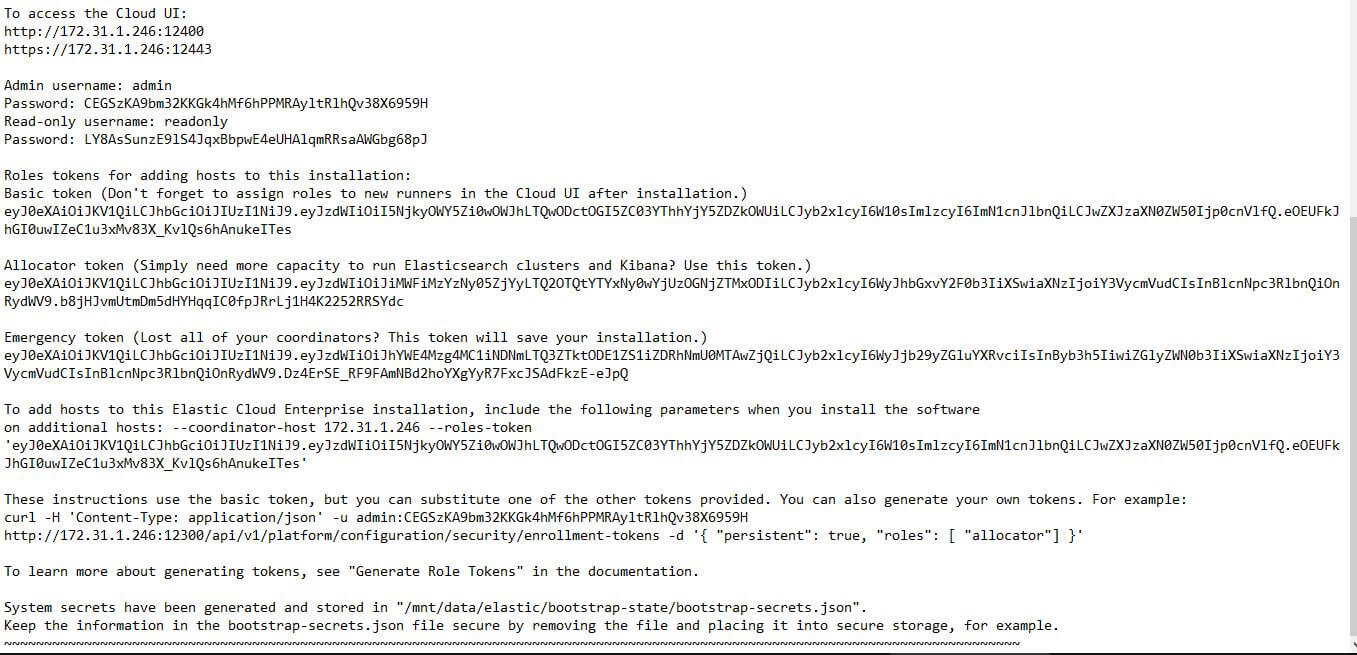
安裝第一台成功
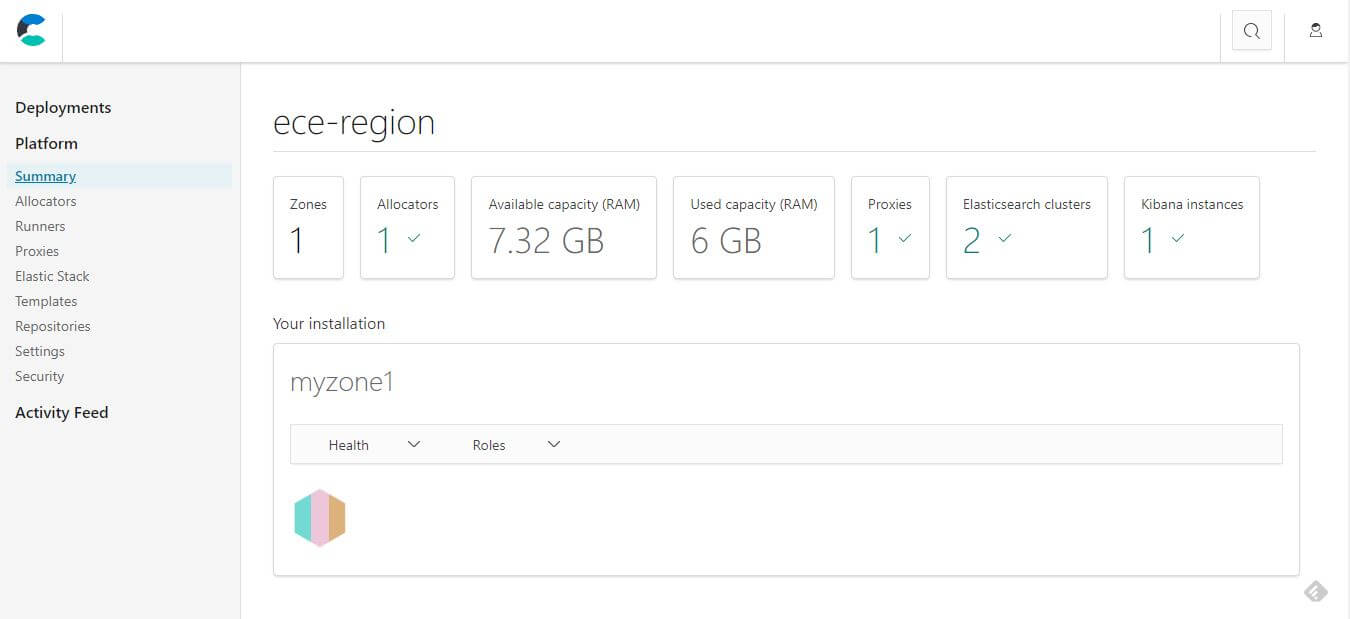
安裝第二台,會用到剛剛安裝成功得到的 token,剛剛存下來的訊息也有提醒我們要記得去設定角色,指定 --availability-zone myzone2,安裝完成後透過 GUI 設定相關的 role。
bash <(curl -fsSL https://download.elastic.co/cloud/elastic-cloud-enterprise.sh) install --cloud-enterprise-version 2.1.1 --availability-zone myzone2 --roles allocator --coordinator-host <IP> --roles-token <TOKEN>
安裝第二台成功
透過 Cloud UI Runners 去幫新的 Runner 配置角色
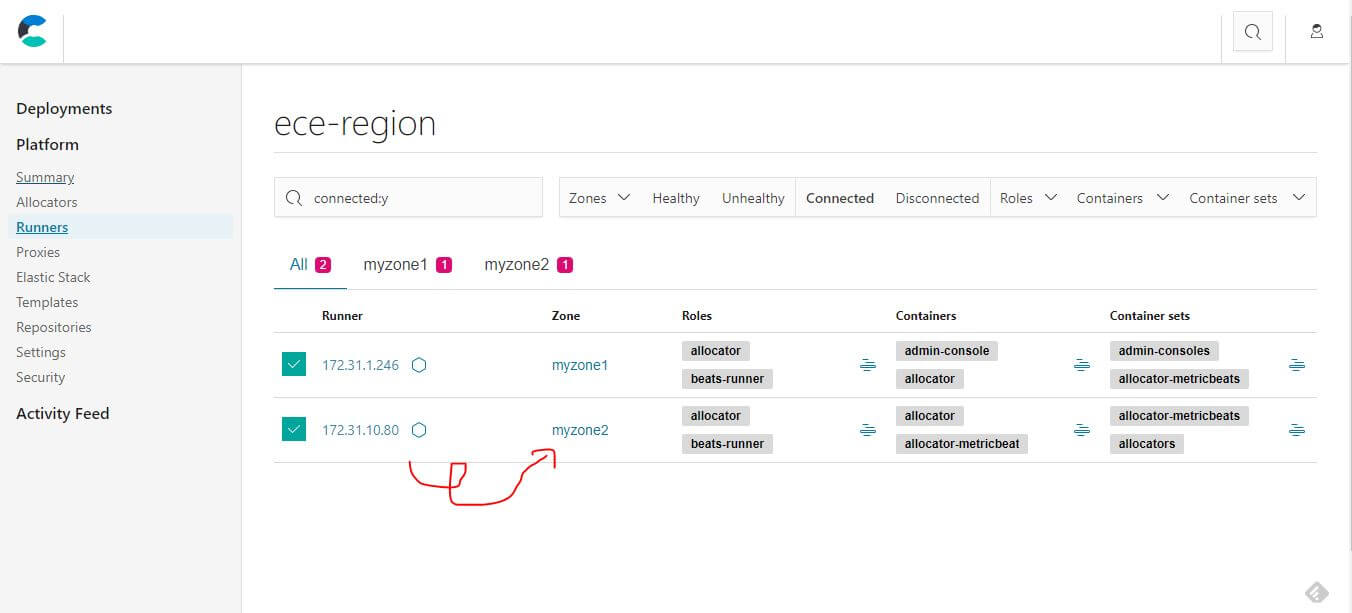
直接全部勾選
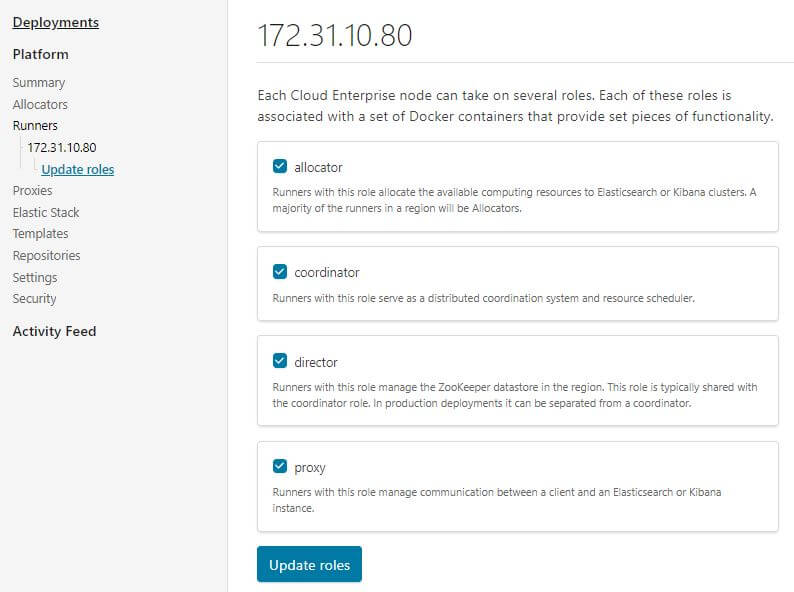
安裝第三台,如果想先指定相關的 role,可以透過指令在第一台先產生特定 token: curl -k -H 'Content-Type: application/json' -u admin:<PASSWORD> https://localhost:12443/api/v1/platform/configuration/security/enrollment-tokens -d '{ "persistent": false, "roles": ["allocator", "coordinator", "director", "proxy"] }'
用剛剛產生的 token 安裝第三台: bash <(curl -fsSL https://download.elastic.co/cloud/elastic-cloud-enterprise.sh) install --cloud-enterprise-version 2.1.1 --availability-zone myzone3 --roles "allocator,coordinator,director,proxy" --coordinator-host <IP> --roles-token <TOKEN>
產生成功
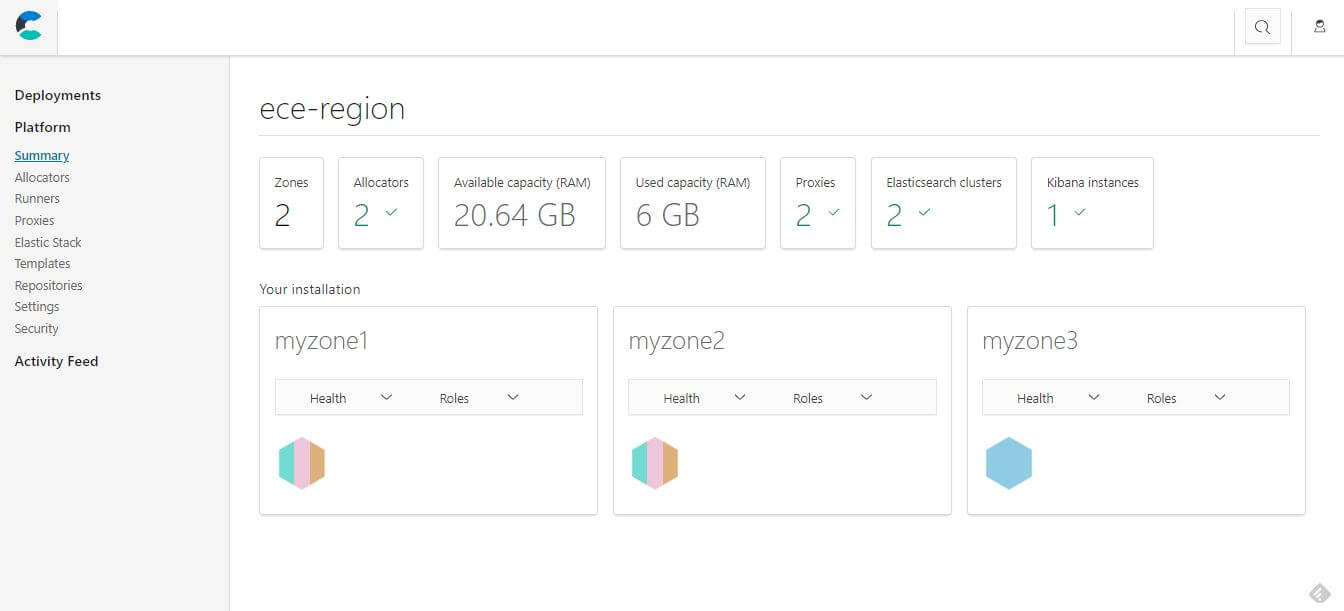
建立 Depeloyments
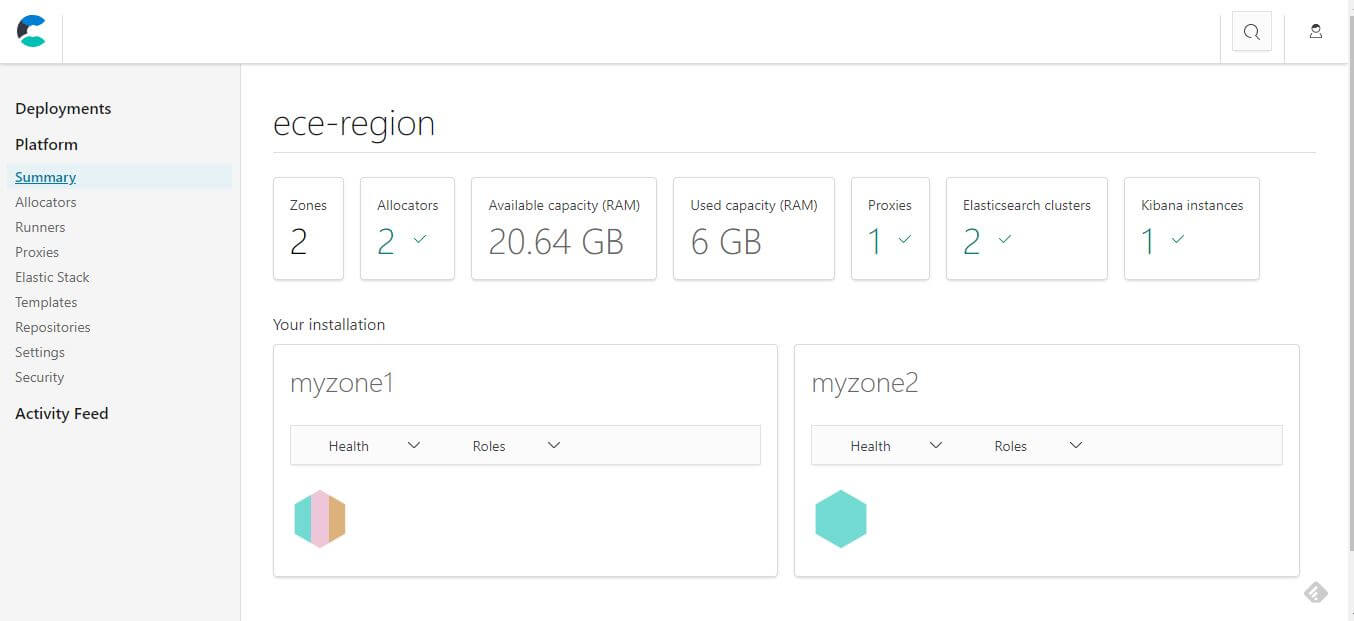
配置完可用區域後,就可以建立一個 Depeloyments,選擇 2 zones 測試。
建立一個 Depeloyments
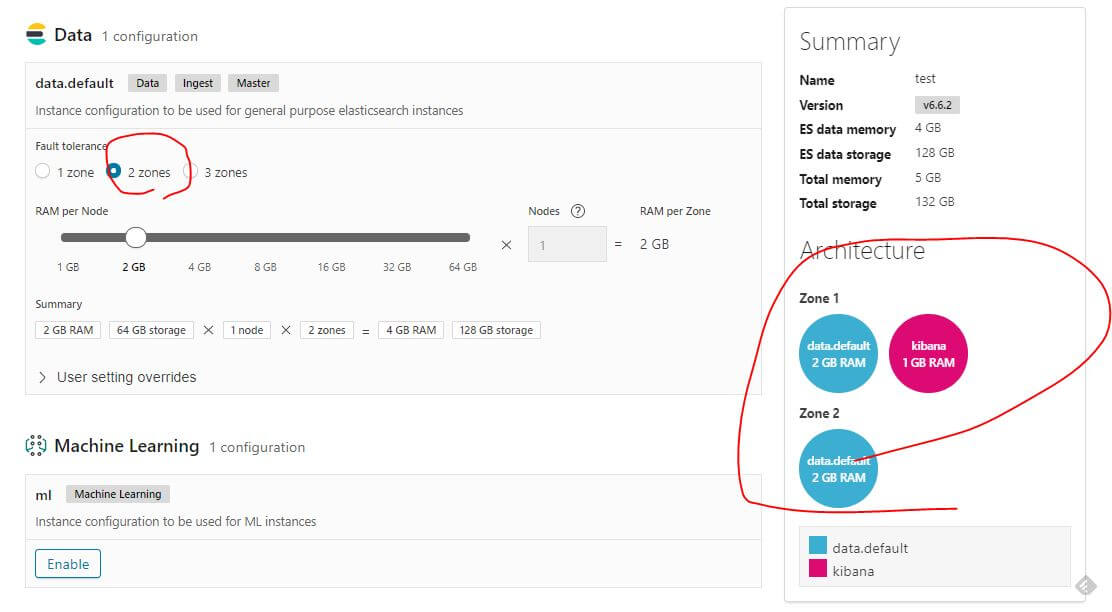
建立成功後會發現另外一個 zone 多出一個 Tiebreakers、Master-eligible 的標籤,所以可以看出 Production 環境最少就是需要三個可用區域,選了 2 zones 的時候會自動把第三個設定成 tiebreaker,決勝局 (Tiebreakers) 的機制在 ECE 中是用來避免分散式架構中的 split brain,腦裂 (split brain) 是指在 HA 的系統架構中,兩個節點的溝通中斷時,本來對外是一個整體的節點分裂成兩個,並且開始搶奪共享的資源,導致系統產生錯誤或是效能下降。
一個整體的節點通常只會有一個 Master Node 主導,其他節點配合,所以需要透過配置 (n/2) + 1 以上的節點來確保法定票數 (quorum) 還有一個第三方仲裁者 (Tiebreakers),當 Master Node 故障出現分裂問題時,就可以透過投票的機制選出新的 Master Node 去取代,Master node 主要是負責新增建立索引、確認節點歸屬的 cluster、決定部屬新節點的位置,Master-eligible 標籤則代表不只有投票功能,也有可能會變成新的 master node。
決勝局 (Tiebreakers)
結論與建議
安裝教學文件
- 小: https://www.elastic.co/guide/en/cloud-enterprise/current/ece-topology-example1.html
- 中: https://www.elastic.co/guide/en/cloud-enterprise/current/ece-topology-example2.html
- 大: https://www.elastic.co/guide/en/cloud-enterprise/current/ece-topology-example3.html
官方的相關建議
- 每個可用區域中至少要有一個 Runner 有 director、coordinator roles
- 每個可用區域中,可以有多個 Runners,確認各區域加起來有足夠的 allocator role 即可
- 如果 clusters 夠多,可以讓 Master Nodes 不需要去處理檢索或是儲存建立索引的工作
- 一台實體機只能容納一個可用區域,避免一台時體機壞了就讓系統停機
- 狀況允許的話,特殊角色可以分別設置在獨立的 Runners,減少未來擴充時的問題
- 至少每個可用區域都要有一個甚至多個 Runners 要有 Proxy Role
喜歡這篇文章,請幫忙拍拍手喔 🤣
站內搜尋
其他相關文章
Elastic APM 基礎教學
2020-09-12
Elastic App Search Quick Start
2020-09-06
最新的文章

Reactjs 問世十年後的開發體驗
2024-04-20Cumulative Layout Shift (CLS)
2024-04-20Google AdSense 新加坡稅務資訊
2024-04-20