什麼是假設檢定及其在 Python 中的實作方法?
假設檢定 (Hypothesis Testing) 是數據分析中判斷觀察結果是否具備「統計顯著性」的核心技術。其核心定義在於:透過建立虛無假設 (H0) 與對立假設 (H1),計算出 p-value 判讀與應用 的機率值。若 p-value 小於顯著水準(如 0.05),則拒絕 H0。在這份 Python 假設檢定教學 中,我們利用 Scipy Stats 範例 與 Statsmodels 庫,對實體資料集執行 Welch’s t-test 或卡方檢定。結合 統計資料視覺化 Python 工具(如 Seaborn),開發者能將抽象的數據差異具象化為圖表,從而精確判別業務指標的變動是源於「真實效果」還是「隨機波動」。
這篇文章將帶領讀者透過 Python 假設檢定教學 (Hypothesis Testing),深入了解如何從數據中驗證假設。我們將使用 statsmodels 中的經典範例資料集 fair 進行 Hypothesis Testing 實作。這份資料集包含 6,367 筆關於婚姻與外遇的統計資訊,我們的目標是透過統計資料視覺化 Python 工具,觀察如職業、婚姻滿意度等變數是否對行為產生顯著影響。
首先感謝 Tainan.py 舉辦這次很棒的年會,讓我有機會分享 Python 在統計檢定上的應用。
環境安裝與 Anaconda 虛擬環境設定
在開始進行 scipy stats 範例實作前,建議先安裝 Python 並配置好開發環境。為了避免函式庫版本衝突,我們強烈建議使用 Anaconda 管理虛擬環境。
首先當然是安裝 python 本人,如果需要在 cmd 中可以執行 python hello.py,需要先在環境變數中增加相關路徑。
https://www.python.org/downloads/
另外 python 預設是將相關函式庫安裝在 global 的環境中,在開發的時候可能會常常需要做實驗,所以我們會需要一個實驗的環境,那就是安裝虛擬環境管理工具 Anacoda,在 node.js 中就是一個避免每次都執行 npm -g 的概念。
https://www.anaconda.com/distribution/
1 | pip3 install scipy # 沒有虛擬環境 |
conda 的常用指令
1 | conda list |
資料集簡介
這次很幸運的可以在社群聚會聽到 Mosky 大大的開示 (投影片在這裡),了解一些檢定在電商上可能的應用。不過由於商業機密的關係,這次講解的範例,主要以 statsmodels 中的範例資料集 fair 來講解,這是一份關於外遇的統計資料, 資料筆數 6367 筆,檢定主要希望可以看到一些有趣的訊息,舉例來說像是職業會不會影響婚外情。
什麼是假設檢定?核心觀念與 p-value 判讀與應用
在進行數據分析時,假設檢定(Hypothesis Testing)幫助我們判斷觀察到的差異是「真有其事」還是「隨機波動」。
- 虛無假設 (Null Hypothesis, H0):這是我們想要推翻的假設,通常表示「沒有差異」或「效果為零」。
- 對立假設 (Alternative Hypothesis, H1):我們真正想要證明的主張。
p-value 判讀與應用是檢定中的關鍵。簡單來說,p-value 代表在 H0 為真的情況下,觀察到目前樣本結果(或更極端結果)的機率。如果 p-value 極小(通常小於 0.05),我們就拒絕 H0,認為結果具有「統計顯著性」。
應用上舉例來說,在某個情境下,我們會定義一個模型,然後期待把資料丟進去算出機率。透過這樣的機率來判斷是否要相信我們的假設,通常這個要依據我們的商品而定,像是筆電負評率 1% 燈泡可能可以到 10%。
檢定可解決的問題
適合回答是否有改變的問題,像是男生和女生平均購物金額是否有差異,或是購買皮卡丘玩偶在不同年齡的男女比例是否有差異。另外一個問題是 sample size 要怎麼決定?假設今天只是猜男女這種五五波問題,sample size 假設需要一千,但如果需要猜測平均轉換率 2%,可能相對要十萬。
- 平均值問題:welche t-test
- 比例問題:卡方檢定
- 找出兩組不同的機率: power analysis
好用工具
在 python 中有相當多的好用工具:
- scipy 中提供相當多的數學計算公式,這次使用較多的為 stats
- pandas 可以從異質資料來源讀取檔案內容,並將資料放入 DataFrame 中,data frame 相當於 execl 中一個 sheet,DataFrame [] 相當於 filter 或是 sql 中的 select
- seaborn 講者大力推薦 python 中畫圖的一個函式庫,將統計數據視覺化,像是 pointplot、countplot
- matplotlib.pyplot 畫完圖如果要顯示可以用這個工具
實作
按照教學上的說明,我們要先安裝相關函式庫,有以下兩種方法:
1 | pip3 install jupyter numpy scipy sympy matplotlib ipython pandas seaborn statsmodels scikit-learn |
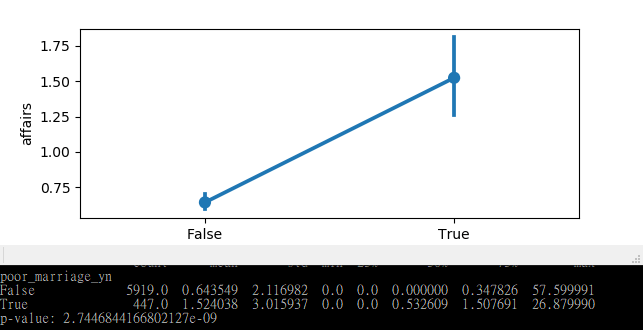
直接進入範例,範例中將看婚姻滿意度對外遇的影響,這裡定義數字小於 2 我們當作不滿意。
1 |
|
結果,最後真的可以看出有明顯差異,所以是否該開始照顧另一半的滿意度了!
FAQ:Python 假設檢定與 p-value 常見問題
Q1:p-value 一定要小於 0.05 才能叫「顯著」嗎?
A:0.05 是學術與業界常用的經驗法則(顯著水準 $\alpha$),但這並非絕對。在高品質的數據分析中,您應根據業務風險來決定。例如,如果是藥物實驗,可能要求 $p < 0.01$;如果是電商按鈕顏色測試,$p < 0.1$ 也許就足以驅動決策。關鍵在於 p-value 判讀與應用 應結合領域知識。
Q2:Welch’s t-test 與普通的 Student’s t-test 有什麼差別?
A:普通的 Student’s t-test 假設兩組樣本的「變異數 (Variance)」相等。然而在現實的 Hypothesis Testing 實作 中,這很難保證。Welch’s t-test 則不需此假設,具有更好的穩健性。在 Python 中使用 sp.stats.ttest_ind(a, b, equal_var=False) 即可輕鬆執行 Welch’s 檢定,避免誤判。
Q3:樣本數 (Sample Size) 的大小會如何影響檢定結果?
A:樣本數越大,檢定力 (Statistical Power) 越高,這意謂著即使是很微小的差異也能被檢測出顯著。然而,這也可能導致「統計顯著但實際無意義」的結果(例如:轉換率只提升了 0.0001% 但 $p < 0.05$)。因此在進行 Python 假設檢定教學 實踐時,除了看 p-value,也應關注效應值 (Effect Size)。
站內搜尋
其他相關文章

Python 爬蟲教學與反爬蟲對策
2021-10-05想學習 Python 爬蟲嗎?本文提供完整的 Python 爬蟲教學,涵蓋 Selenium 與 Requests 兩大主流工具的實戰範例。深入解析網頁資料擷取技術、常見的反爬蟲機制與應對對策,助您快速掌握從網頁自動化到高效數據抓取的關鍵技能。
Python FastAPI 入門與 Pydantic 驗證
2021-10-08正在找尋高效的 Python Web 框架嗎?本文提供 Python FastAPI 入門教學,解析如何利用 FastAPI 快速開發具備自動化文件的 API。涵蓋 Pydantic 資料驗證、非同步 API 開發 (ASGI) 以及 Swagger 互動式文件,助您大幅提升開發效率並減少程式錯誤。
Mongoose 深度指南與 MongoDB 整合
2019-09-07深入淺出 Mongoose,理解 ODM 概念與 MongoDB 資料庫的無縫操作.從 Schema 設計到 API 整合,快速掌握 Mongoose 在後端開發中的核心應用,提升開發效率。
最新的文章
葬送的芙莉蓮與她的無路之路
2026-04-03AI Agent Skill 實戰
2026-03-21AI Agent Skill 開發指南
2026-03-20