什麼是網路安全異常偵測 (Anomaly Detection)?
網路安全異常偵測 (Anomaly Detection) 是一種基於 機器學習 (Machine Learning) 的主動防禦技術,旨在識別網路流量中偏離「正常基準」的異常行為。不同於傳統基於規則(Rule-based)的攔截,異常偵測能透過對歷史數據(如 DNS 請求頻率、封包大小、Host Name 結構)的深度學習,自動發現潛在的威脅,如 DNS Tunneling(隱蔽通道傳輸)或 DDoS 攻擊。透過 Elastic Anomaly Detection 工具,企業能建立自動化的監控模型,即時發現在複雜網路環境中難以察覺的進階持續性威脅 (APT),從而大幅提升資安監控解決方案的響應速度與精準度。
在日益複雜的網路威脅環境中,傳統的資安防護手段已難以應對層出不窮的進階攻擊。因此,部署一套強大的資安監控解決方案,並結合前瞻性的網路安全異常偵測能力,成為企業不可或缺的一環。
本文將深入探討如何運用 Elastic Machine Learning 應用中的 Elastic Anomaly Detection 教學,針對常見的 DNS 攻擊偵測方法進行實戰演練。
DNS 常見攻擊與可能的偵測方法
DNS 的用途是把比較難記的 IP 跟比較好記的網域進行對應連結。運作原理簡單來說就是給網域回答 IP 地址,網路上目前也提供非常多 WHOIS 的相關服務。
WHOIS
問網域會有兩種詢問的方法:
- Recursive: Client 透過 DNS 代理去問。
- Iterative: Client 慢慢問,不會一次就問到結果。
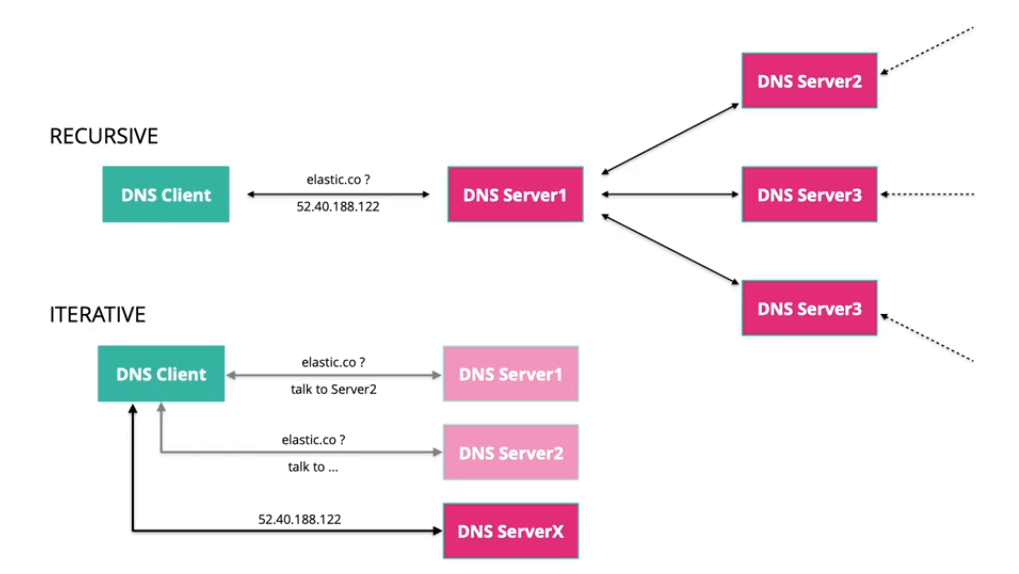
Recursive VS Iterative
DNS 主要會有以下紀錄
- A/AAAA: 網域對應到 IPv4 / IPv6 的位置
- CNAME: 網域對應到另一個網域
- MX: 紀錄這個網域的郵件伺服器
- NS: Name Server 找不到可以去問的地方
常見 DNS 攻擊模式
越多人用的服務也就越容易成為攻擊目標:
- DDoS / DNS Amplification: 大流量癱瘓攻擊。
- DNS Cache Poisoning: 加入偽造記錄,將使用者導向惡意 IP。
- MITM (中間人攻擊): 介入傳輸竄改資料。
- DNS Hijacking: 直接控制 DNS 記錄進行綁架。
- DNS Tunneling: 將其他協定封裝在 DNS 中傳輸以規避防火牆。開源工具如 iodine 或 DNS2TCP。
可憐的主機商,又被 DDoS 了
C&C 與威脅地圖
C&C (Command & Control Server) 是控制僵屍網路的主控伺服器。要達到監控威脅,目標是去偵測出 C&C 伺服器相關的活動。如果可以在被攻擊前,透過分析數據提早抓到惡意軟體 (Malware) 在溝通,也許就能預防。
威脅地圖
Elastic Machine Learning:DNS 資料分析實戰
下面會使用教學範例中提供的 security-analytics-packetbeat-* 來示範:
建立 Datafeed:
設定內容為{"term":{"type":{"value":"dns","boost":1}}}。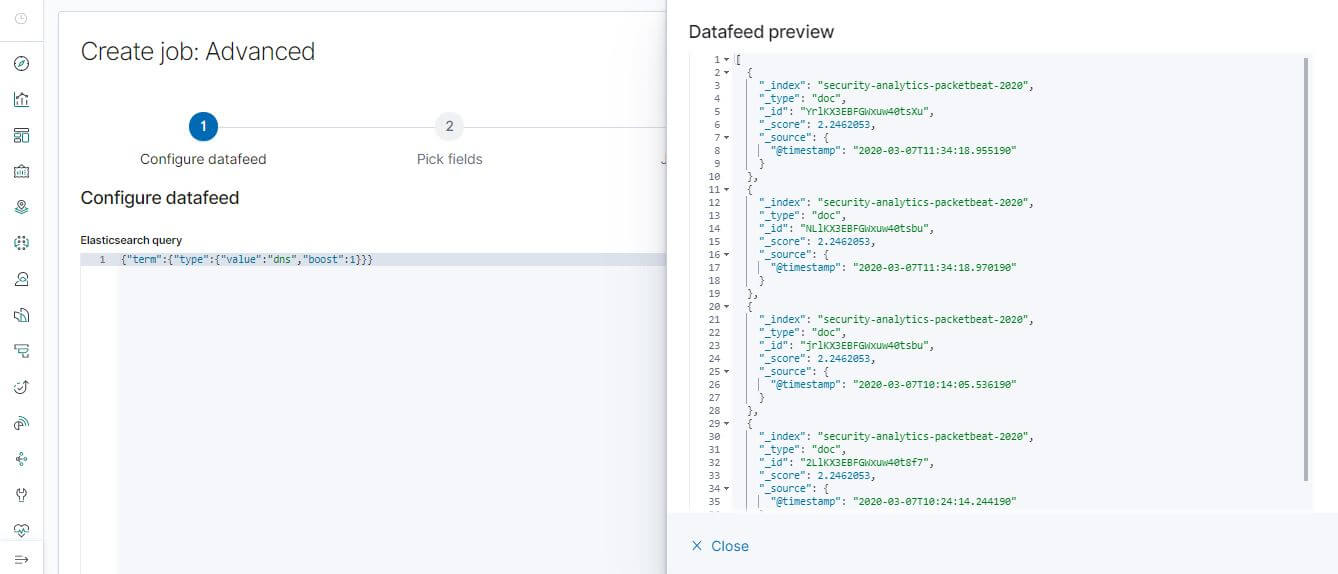
設定 Detector:
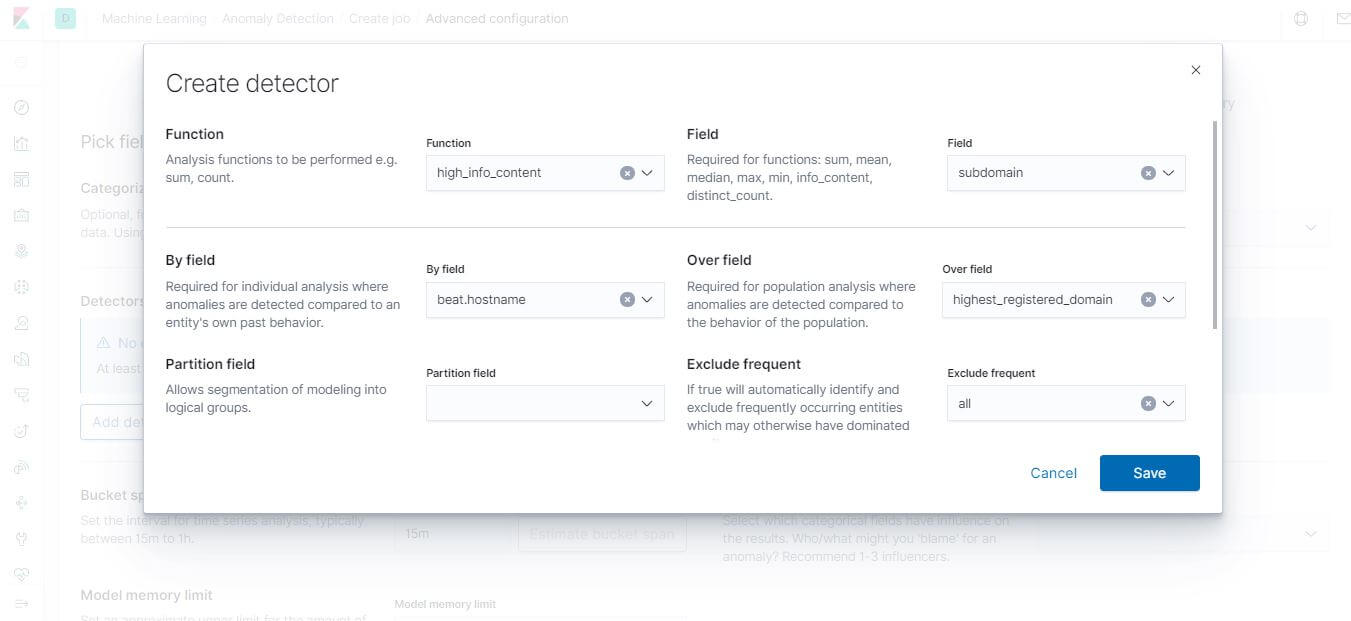
設定 Bucket Span 及 Influencer:
下一步其他都用預設值即可。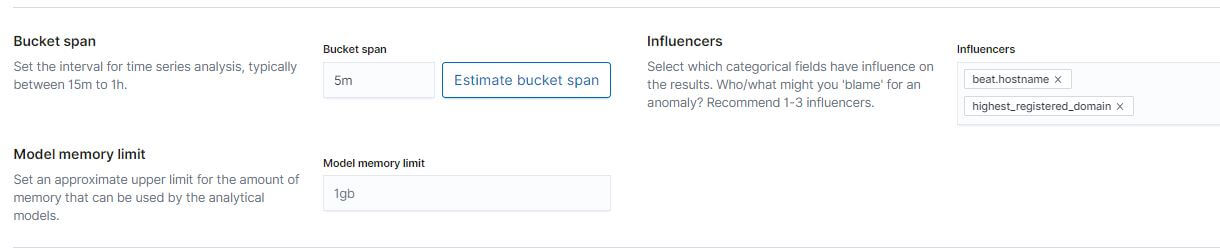
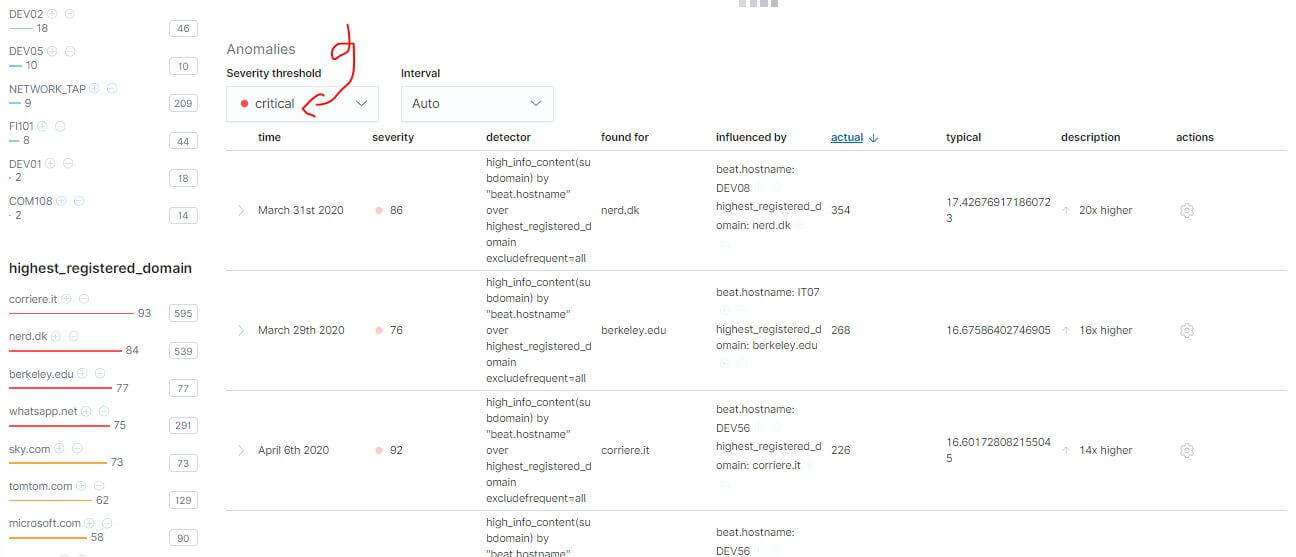
偵測結果分析
透過 Anomaly Explorer,可以馬上看出哪個網域或 Host Name 最有可能出現問題。面板右半邊是時間分析圖表,左半邊是 Influencer 相關聚合統計。
Critical Anomalies
看完後發現相關步驟並不難,難的是要知道怎麼設定配置。Elastic 提供了一些常見配置教學:OOTB Machine Learning Jobs 與 機器學習 Functions 文件。
FAQ:資安異常偵測常見問題
Q1:什麼是 Bucket Span?在資安監控中該如何設定?
A:Bucket Span 是機器學習分析數據的時間窗口大小。對於資安偵測,建議設定在 5 分鐘到 15 分鐘之間。太短會產生過多雜訊與誤報,太長則可能導致偵測反應遲鈍,無法及時攔截快速發生的攻擊行為。
Q2:為什麼在異常偵測任務中需要設定 Influencer?
A:Influencer 是指最可能導致異常發生的欄位(如 client_ip 或 query)。設定 Influencer 的好處在於,當系統偵測到異常分數很高時,能直接指引管理員:「是哪一個特定 IP 造成了這個問題」,大大縮短了事故調查與排查的時間。
Q3:機器學習偵測與傳統規則 (Rules) 監控有什麼不同?
A:傳統規則像是一道死牆(例如:1 秒內請求 > 1000 次就阻斷),容易被進階攻擊規避。機器學習偵測 則是學習「行為曲線」,即便攻擊流量不大,但只要與該主機平常的通訊模式不符,模型就能識別出它是潛在威脅,適合用來對抗零日攻擊或變種病毒。
站內搜尋
其他相關文章
Elastic APM 整合 RUM 即時監控
2020-09-12想精準找出應用程式的效能瓶頸嗎?本篇指南深入探討 Elastic APM 的核心原理與實作。我們將示範如何為 Node.js 服務配置 APM Agent,透過 Spans 與 Transactions 追蹤 API 回應時間,並利用 Kibana 實現視覺化監控。前 150 字直接回答 APM 定義,助您建立高品質的實時應用監控體系,優化系統響應速度。
Elastic App Search 全文檢索教學
2020-09-06本篇快速指南將示範如何使用 Elastic App Search,透過 Elastic Cloud Search 服務在幾分鐘內完成搜尋引擎架設。深入了解全文檢索核心概念與 App Search 優化技巧,助您輕鬆建立高效搜尋功能,大幅提升資料檢索效率與使用者體驗。

Elasticsearch 通訊加密與傳輸安全
2020-09-14本文深入探討如何在 Elasticsearch 叢集內外部啟用加密傳輸,保障敏感資料安全。學習使用 TLS/SSL 配置節點間、Kibana、Beats、Logstash 及客戶端應用的安全溝通,並介紹 `elasticsearch-certutil` 工具,提升 Elastic Stack 環境安全性。
最新的文章
葬送的芙莉蓮與她的無路之路
2026-04-03AI Agent Skill 實戰
2026-03-21AI Agent Skill 開發指南
2026-03-20