什麼是 Python 爬蟲及其核心實作方法?
Python 爬蟲教學 的核心在於自動化地從網路上採集數據。高品質的 網頁資料擷取 主要分為兩種實作路徑:1. Requests 爬蟲範例:利用 HTTP 請求直接獲取靜態 HTML 或 JSON,速度極快且節省資源,適合 104 職缺抓取等 API 數據源;2. Selenium 爬蟲實作:模擬真人操作瀏覽器,能處理 JavaScript 渲染的動態網頁及點擊互動。實踐過程中應遵守 robots.txt 協定 與控制存取頻率,避免對目標伺服器造成負擔。掌握 反爬蟲機制與對策(如處理驗證碼或偽裝 User-Agent),是開發穩健、高效 數據採集策略 的關鍵技術。
什麼是網站爬蟲與網頁資料擷取?
網站爬蟲(Web Crawler)或稱為網頁資料擷取(Web Scraping),是一種自動化瀏覽網路並提取資訊的技術。透過編寫程式,開發者可以將爬取的頁面內容儲存,蒐集網路上的海量資源供後續分析、研究或商業用途使用。
舉一個大家都聽過的應用,Google 搜尋引擎背後其實也是透過強大的爬蟲技術來將全球網站資料存下來進行索引,進而提供精準的搜尋服務。
由於爬蟲存取網站的過程會消耗目標站台的系統資源,因此在進行 Python 爬蟲實作時,開發者必須遵守以下兩大核心價值觀:
- 不要打爆對方:控制存取頻率,避免造成對方伺服器過載。
- 遵守 robots.txt 協定:尊重網站定義的爬取規則,避開禁止存取的路徑。
主流 Python 網站爬蟲工具比較
在 Python 的生態系中,進行網頁資料擷取最常見的工具主要有以下兩種,各有其優缺點與適用場景:
- Selenium:萬用且學習門檻低,能模擬真人操作瀏覽器,適合處理需要執行 JavaScript 或複雜互動的動態網頁。
- Requests:執行效率極佳,主要處理靜態 HTML 文本,由於不需讀取圖片或渲染 UI,抓取速度遠快於 Selenium。
常見的 Requests 爬蟲範例情境包括:
- 一步可爬:資料直接嵌入在 HTML 表格中。
- 查詢後爬:需透過搜尋篩選框(API 參數)取得資料。
- 先登入後爬:結合 Session 或 Cookie 進行身分驗證。
- 驗證碼破解
- Tesseract
- Tesseract + keras
- 驗證碼破解
網站反爬蟲機制與對策
為了保護網站資料與頻寬,許多站台會建立反爬蟲機制。了解這些障礙有助於開發者寫出更強健的爬蟲程式:
- 身分驗證:要求登入後才能查詢,檢查 Header (如 User-Agent) 或 Cookie。
- 動態防護:CSRF Prevention Salt 改成一次性、動態變更 HTML 結構。
- 驗證碼 (CAPTCHA):選圖片、加減乘除,阻斷自動化腳本。
- 使用者干擾:隨機跳出 Pop-up 視窗或 Alert 警告。
- 資料混淆:將 Table 資料轉成圖片或 PDF,增加網頁資料擷取的難度。
- DOM 結構變化:在 xPath 路徑中新增隱藏的 DIV,在不影響使用者體驗的情況下干擾 xPath 爬蟲。
此外,身為站長也應定期進行流量壓力測試,防止伺服器被爬蟲拖垮:
- 流量監控:從 Google Analytics (GA) 或伺服器 Log 分析異常流量並封鎖。
- 壓力測試工具:如 Python 的
locust套件。
Python Selenium 爬蟲實作教學
由於環境設定較複雜,建議初學者使用 Google Colab。這是一個基於雲端的 Jupyter Notebook 環境,提供免費的 GPU 資源與預載的 Python 環境。
以下是一個針對玉山銀行網站進行網頁資料擷取的實戰範例:
- Colab 需要先安裝才能夠使用 selenium
1 | !pip install selenium |
- 引入資料處理常見的 pandas、還有本次爬蟲主角 selenium
1 | import pandas as pd |
- 透過 webdriver 指定瀏覽器為 chrome,並且設定相關參數,最後透過瀏覽器開啟網站
1 | chrome_options = webdriver.ChromeOptions() |
- 透過 Pandas 套件提供的
read_html()輕鬆讀取網頁中的<table>表格,這裡就直接選取第一個
1 | pd.read_html(browser.page_source)[0].head() |
- 或著我們也可以透過 xpath 來進行指定 html 的範圍,然後也是一樣餵給
read_html()
1 | element_xpath = '//*[@id="mainform"]/div[10]/div[2]/div[2]/table[1]' |
- 如果遇到彈跳視窗來阻擋,一樣可以透過 xpath 先找到,然後透過 JavaScript 把 Element 從 Dom 中移除。
1 | # 移除彈跳視窗 |
Python Requests 爬蟲範例與 104 職缺抓取
requests 不同於 Selenium,抓取下來的是純 HTML 文本或 JSON 資料,不包含圖片等資源,對伺服器負擔小且速度極快。以下示範如何透過 Python 爬蟲教學中的進階技巧,抓取 104 人力銀行的職缺資料。
這個實戰案例中,我們會透過分析 104 的 API 參數來取得特定產業與地區的數據:
- indcat: 產業別
- area: 地區
- page: 頁數
- 引入資料處理常見的 pandas、還有本次爬蟲主角 requests
1 | import requests |
- 網站有基本反爬蟲所以需要設定 Headers 來騙過伺服器,最後透過 requests 開始抓取資料
- User-Agent (用戶端)資訊: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.135 Safari/537.36’
- Referer (從哪裏來): ‘https://www.104.com.tw/‘
1 |
|
- 透過 Pandas 套件提供的
DataFrame將資料存下來,先顯示個三筆看看
1 | pd.DataFrame(resp.json()['data']['list']).head(3) |
- 當然一次爬個 10 頁也是沒問題
1 | df = [] |
- 接著是整理地區跟產業別的篩選條件,舉地區資料如下,會透過 explode 把 array 中的 n 做展開,然後透過 apply 去整理資料,最後透過 loc 把剛剛展開的 n 拿掉生成新的 Dataframe
第 0 筆的 n 資料如下:
1 | [ |
1 |
|
- 跑迴圈把所有的資料抓下來
1 | df = [] |
- 把檔案存起來,收工
1 | df.to_excel('./data/job_abs.xlsx') |
為了避免爬太久,有把條件減少,Github 中完整的 Gist 如下:
FAQ:Python 爬蟲常見問題
Q1:我應該在什麼時候選 Selenium,什麼時候選 Requests?
A:Requests 爬蟲範例 適合「資料即在源碼中」的靜態網頁,其優點是執行效率極高且佔用系統資源極少。如果您遇到需要「模擬點擊」、「滾動加載」或網頁內容是透過高度複雜的 JavaScript 動態生成的,則建議使用 Selenium 爬蟲實作。簡單來說:追求速度選 Requests,追求萬用選 Selenium。
Q2:如何降低爬蟲被目標網站封鎖的機率?
A:高品質的 數據採集策略 包含:1. 偽裝真實的 User-Agent,讓伺服器誤以為是瀏覽器存取;2. 增加隨機的 sleep 延遲,避免短時間內發送大量請求;3. 使用代理 IP (Proxy) 進行流量分散;4. 嚴格遵守 robots.txt 協定。此外,若網站提供 API,應優先使用官方 API 而非強行爬取。
Q3:自動化爬取網頁資料是否存在法律風險?
A:是的。在進行 網頁資料擷取 前,務必閱讀該網站的使用條款。通常非商業用途、學術研究且不影響對方系統運作的爬取較具彈性,但若涉及爬取個人隱私、商業機密資料或造成對方伺服器損失,則可能觸法。高品質的開發者應始終堅持「數據共享,技術無害」的原則。
站內搜尋
其他相關文章
Python FastAPI 入門與 Pydantic 驗證
2021-10-08正在找尋高效的 Python Web 框架嗎?本文提供 Python FastAPI 入門教學,解析如何利用 FastAPI 快速開發具備自動化文件的 API。涵蓋 Pydantic 資料驗證、非同步 API 開發 (ASGI) 以及 Swagger 互動式文件,助您大幅提升開發效率並減少程式錯誤。
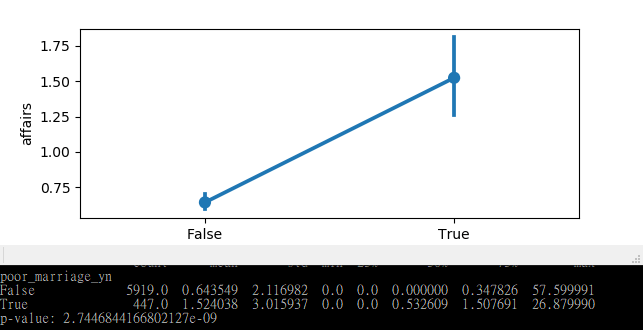
Python 假設檢定實作與數據分析
2019-08-01想掌握數據分析的核心技術嗎?本文提供深入淺出的 Python 假設檢定教學,從 Hypothesis Testing 的基本觀念到 p-value 的實務判讀。結合 Scipy、Statsmodels 與 Seaborn,透過外遇統計資料集實戰演練資料視覺化,助您從海量數據中洞察關鍵趨勢。

Mongoose 深度指南與 MongoDB 整合
2019-09-07深入淺出 Mongoose,理解 ODM 概念與 MongoDB 資料庫的無縫操作.從 Schema 設計到 API 整合,快速掌握 Mongoose 在後端開發中的核心應用,提升開發效率。
最新的文章
用 Loop Engineering 讓 AI 不再需要你盯著它
2026-07-19你的每個 Prompt 都在燒錢
2026-06-28《隱性潛能》AI 不讓你變聰明,讓你的潛能被放大
2026-06-27